이번 논문은 ELMo라고 불리는 모델을 정리한다.
Deep contextualized word representations
Deep contextualized word representations
ME Peters, M Neumann, M Iyyer, M Gardner, C Clark, K Lee, L Zettlemoyer, NAACL, Best Paper, 2018 - 인용 횟수 9,337번
scholar.google.com
Abstract
- 본 논문은 단어 사용의 복잡한 특성(구문, 의미)과 이러한 사용이 언어적 문맥(다의성 모델링)에 따라 어떻게 다른지를 모두 모델링하는 새로운 유형의 심층 문맥화 된 word 표현을 소개한다.
- 단어 벡터는 큰 텍스트 말뭉치에서 사전 훈련된 biLM의 내부 상태에 대해 학습된 함수에 해당한다. 이러한 표현은 기존의 모델들에 쉽게 추가될 수 있으며 질문/답변, 감성 분석 등의 테스크에 적용 가능하다.
- 결과적으로, NLP문제 전반에 걸쳐 성능을 향상할 수 있음을 보였다. 또한, downstream 모델이 서로 다른 유형의 semi-supervision 신호를 혼합할 수 있도록 사전 훈련된 네트워크의 내부가 중요하다는 분석을 제시한다.
1 Introduction
- 사전 훈련된 단어 표현들은 많은 신경 언어 이해 모델의 핵심 구성 요소이다. 그러나, 고품질의 표현을 배우는 것은 어렵다. 이상적으로는 단어 사용의 복잡한 특성과 언어적 맥락에 따라 다른 점을 모두 모델링해야 한다. 이러한 점을 본 연구에서 해결하고 기존 모델에 쉽게 통합할 수 있도록 하며 다양한 언어 이해 문제에 걸쳐 고려된 사례에 대한 성능 향상을 성공한다.
- 본 연구에서 제시한 표현법은 전체 입력 문장의 기능인 표현이 할당된다는 점에서 전통적인 단어 유형 임베딩과 다르다. 여기서는 큰 텍스트 말뭉치에서 결합된 언어 모델을 목표로 훈련된 Bi-LSTM에서 파생된 벡터를 사용한다. 그래서 ELMo (Embeddings from Language Models)라고 부르게 된다.
- 이러한 접근 방식은 이전의 방식들과 달리 ELMo는 biLM의 모든 내부 계층의 함수라는 점이 특별한 점이다. 즉, 최종 task를 위해 각 입력 단어 위에 쌓인 벡터의 선형 조합을 학습하고, 최상위 LSTM 레이어를 사용하는 것보다 성능이 크게 향상된다.
- 이러한 방식으로 내부 상태를 결합하면 풍부한 단어 표현이 가능하다. 즉, 상위 수준 LSTM 상태가 단어 의미의 문맥적 종속 측면을 잡아내고, 하위 수준 상태는 구문적 관점을 살피는 데 사용할 수 있다. 이러한 모든 신호를 동시에 노출하는 것은 매우 유익하며 학습된 모델이 각 최종 작업에 가장 유용한 semi-supervision 유형을 선택할 수 있다.
- 본 연구에서 보여준 실험들은 ELMo 표현이 매우 잘 작동함을 보여준다. 6가지의 task들에 대해 기존 모델에 쉽게 추가할 수 있음도 보여준다. ELMo를 추가하면 최대 20%의 상대 오류 감소를 보여주며, 모든 경우에 대해 기술 향상을 보여준다.
- ELMo와 CoVe (MT-LSTM의 결과로 생성된 representation을 이용한 context vectors)를 모두 분석한 결과 깊은 표현이 LSTM의 최상위 레이어에서 파생된 표현보다 성능이 우수하다.
2 Related work
- 이전에 제안된 방법은 단어에 대해 단일 문맥 독립 표현만 허용한다. 그래서, 각 단어 의미에 대해 별도의 벡터를 학습해야 했다.
- 이러한 단점을 해결하기 위해 context2vec경우 Bi-LSTM를 사용하여 pivot 단어 주변의 문맥을 인코딩한다. 이를 위해 pivot 단어 자체를 포함하여 지도 신경망 기계 번역 시스템(CoVe) 또는 비지도 언어 모델의 인코더로 계산한다.
- 해당 방법들은 deep biRNN의 서로 다른 레이어가 서로 다른 유형의 정보를 인코딩하는 것으로 나타났다. 예를 들어, deep LSTM의 하위 수준에서 다중 작업 구문 감독을 도입하면 종속성 구문 분석 또는 CCG super과 같은 상위 수준 전반적인 성능을 향상할 수 있었다.
- 또 다른 예로, RNN 기반 인코더-디코더 기계 번역 시스템에서 2개 계층 LSTM 인코더의 첫 번째 계층에서 학습된 표현이 두 번째 계층보다 POS 태그를 더 잘 예측함을 보여주었다.
- 마지막 예로, 단어 문맥을 인코딩하기 위한 LSTM 최상위 계층은 단어 의미의 표현을 학습하는 것으로 나타났다.
- 본 연구에서는 레이블이 지정되지 않은 데이터로 biLM을 사전 훈련하고, task에 적합하도록 가중치를 수정해 가는 방식을 채택한다.
3 ELMo: Embeddings from Language Models
- ELMo 단어 표현은 전체 입력 문장을 고려하는 기능이다. 내부 네트워크 선형 함수로 문자 합성곱이 있는 2개 계층의 위에서 계산되며, biLM이 대규모로 사전 훈련된다. 그리고 기존의 광범위한 신경 NLP 구조에 통합되는 semi-supervised 학습을 수행할 수 있다.
3.1 Bidirectional language models

- N개의 토큰 시퀀스 (t1, t2,..., tN)가 있을 때, 순방향 언어 모델의 (t1, t2,..., tk-1)에 의해 주어진 tk의 확률에 의해 정해진다.
- 문맥 독립적인 k번째 단어 표현을 xLM_k이라고 할 때, L개의 LSTM 계층에 입력을 통과시킨다. 각 위치 k에서 LSTM 계층은 문맥 종속 표현 h(LM_k, j) 벡터를 출력한다.
- 최상위 계층 LSTM의 출력, h벡터(LM_k, L)는 softmax 계층으로 다음 토큰 tk+1을 예측하는 데 사용된다.
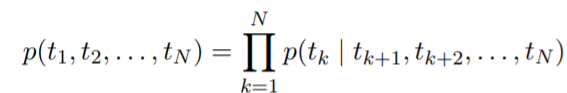
- 역방향 LM은 순방향과 유사하지만, 시퀀스를 역으로 실행하여 미래의 context가 주어지면 이전 토큰을 예측한다.
- 즉, tk+1,..., tN이 주어졌을 때 h벡터(LM_k, j)를 계산한다.

- biLM은 순방향 LM과 역방향 LM을 모두 결합한다. 현재 논문의 공식은 순방향과 역방향의 로그 가능성을 공동으로 최대화하도록 한다.
- 토큰 표현(theta_x)과 Softmax 레이버(theta_s) 모두에 대한 매개변수를 정방향 및 역방향으로 결합하고, 각 방향에서 LSTM에 대한 별도의 매개 변수들과는 다르게 유지된다.
3.2 ELMo
- ELMo는 biLM의 중간층들의 표현들을 task-specific 하게 결합, biLM의 L개 layer에는 각 토큰 tk당 2L+1개의 표현을 계산

- 최종적으로 모든 층에서 생성한 표현들을 결합해서 하나의 벡터로 생성
- s_task는 softmax-표준화된 가중치이고, 감마_task는 최종 벡터의 크기를 결정, 최적화 과정에서 중요한 역할
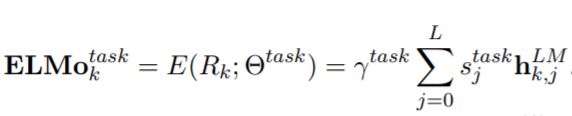
3.3 Using biLMs for supervised NLP tasks
- 사전 훈련된 biLM과 NLP task를 위한 지도 학습 구조에 대해, task model을 개선하기 위해 biLM을 사용한다.
- 우선 각 단어를 위한 계층 표현과 biLM을 훈련한다. 그리고, 표현들의 선형 결합을 학습하기 위해 task model의 끝에 위치하게 한다.
구체적으로,
1. biLM 없이 지도 학습 모델의 가장 낮은 계층을 고려한다. 대부분의 지도 학습 NLP 모델들은 가장 낮은 계층에서 보통의 구조를 공유한다. 그리고 여기에 ELMo를 더할 수 있게 한다.
2. token들의 sequence에 대해, 사전 훈련된 단어 임베딩 및 선택적으로 문자 기반 표현을 사용하여 각 토큰 위치에 대해 컨텍스트 독립적 토큰 표현 xk를 형성한다. 그런 다음 모델은 일반적으로 양방향 RNN, CNN 또는 피드 포워드 네트워크를 사용하여 상황에 맞는 표현 hk를 형성한다.
3. ELMo를 지도 학습 모델에 추가하기 위해 biLM의 가중치는 freeze(고정)한다. 그리고 ELMo 벡터를 ELMo_task_k에 xk와 함께 고정한다. 또한, RNN task에서 [xk;ELMo_task_k] ELMo를 다음과 같이 연결한다.
4. 지도 모델의 나머지 부분은 변경되지 않은 상태로 유지되기 때문에 ELMo의 추가와 같은 것은 보다 복잡한 신경 모델 context에서 발생 가능하다.
5. 마지막으로, ELMo에 적당한 양의 드롭아웃을 추가하고 loss에 weight 람다||w||_2^2를 추가할 수도 있다. 이는 biLM 레이어의 평균에 가깝게 유지하기 위해 유도 bias를 부과하는 것이다.
3.4 Pre-trained bidirectional language model architecture
- 사전 훈련된 biLM은 양방향 학습이 가능하며, LSTM 계층 간에 residual connection을 추가하도록 했다.
- 최종 모델은 4096개의 unit과 512차원의 출력을 제공한다. 또한, 첫 번째 레이어에서 두 번째 레이어 층을 residual connection으로 연결하여 전반적으로 2개의 LSTM을 사용한다.
- 문맥을 고려하지 않는 임베딩은 2048 문자 n-gram convolution filter를 사용하고, 2개의 highway layer와 512차원의 출력을 제공한다. 이러한 구조를 기반으로 biLM은 입력에 대해 3개의 표현을 생성하게 된다.
- 1B Word Benchmark에서 10 epoch 동안의 훈련 이후, 순방향 CNN-BIG-LSTM의 경우 역방향 perplexity는 39.7을 제공했다. 순방향 perplexity와 역방향 perplexity는 거의 유사하나, 역방향의 경우가 조금 더 낮게 측정되었다.
- 사전 훈련된 biLM은 모든 작업에 대한 표현 계산이 가능했다.
4 Evaluation
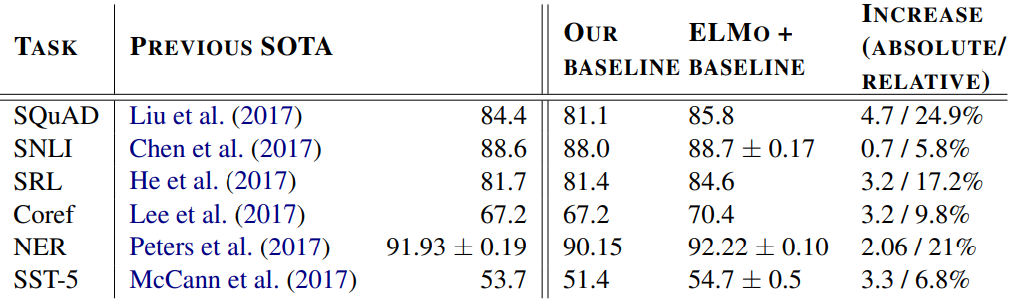
- 표 1은 6가지 NLP 작업의 다양한 set에 대해 ELMo의 성능을 보여준다. 모든 작업에서 ELMo를 추가하기만 하면, 기존의 모델 성능에 비해 6~20% 범위의 상대 오차가 감소함을 확인했다.
Question answering
- 답변이 포함된 Wikipedia 단락의 범위인 100,000개 이상의 crowd sourced 질문/답변 쌍이 포함되어 있다. baseline 모델에 EMLo를 추가한 후 test set의 F1 score는 향상되었으며, 전반적으로 성능개선을 나타냈다.
Textual entailment
- 텍스트 함축 task는 전체가 주어졌을 때 가설이 참인지 여부를 결정하는 작업이다. biLSTM을 사용한다. ELMo를 추가하면 정확도가 평균적으로 0.7% 향상되며, 앙상블 최고 성능을 능가한다.
Semantic role labeling
- 누가 누구에게 무엇을 했는가에 대한 응답을 가리키는 SRL 시스템은, deep biLSTM을 사용했다. ELMo를 추가할 때 3.2 % 성능 향상을 보여주었다.
Coreference resolution
- 상호 참조 resolution은 동일한 엔티티를 참조하여 text의 mention을 클러스터링 하는 작업이다. biLSTM과 Attention 메커니즘을 사용하였으며, ELMo 추가 시, F1 score가 평균적으로 3.2% 향상되었다.
Named entity extraction
- ELMo를 포함한 biLSTM-CRF는 평균 92.22%의 F1 score을 달성했다.
Sentiment analysis
- 영화 리뷰 문장을 설명하기 위해 5가지의 레이블을 나누어 이 중 하나를 선택하는 작업을 수행했다. CoVe를 ELMo를 교체하면 정확도가 약 1% 향상되는 것을 알 수 있었다.
5 Analysis
- 이 section에서는 주요 주장에 대한 검증과 함께 ELMo의 새로운 측면을 검토하기 위해 특정 부분을 빼거나 교체하여 해당 부분의 역할을 알아보는 분석을 수행한다.
5.1 Alternate layer weighting schemes
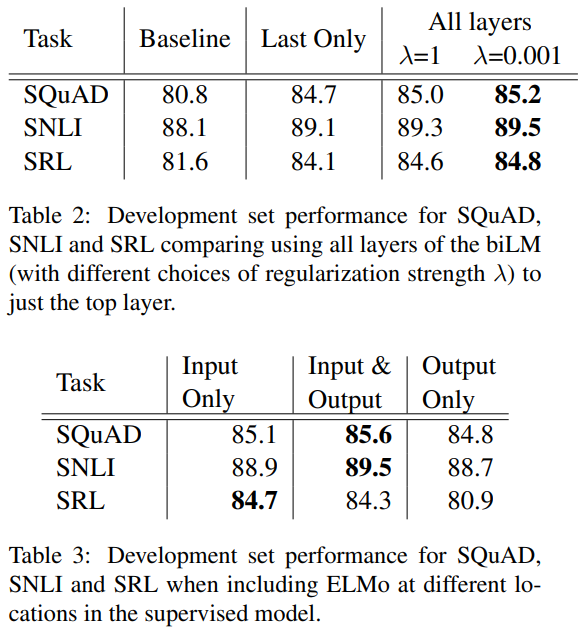
- down stream작업에서 심층 context 표현을 사용한다. 최상위 layer만 사용하는 작업보다 성능이 향상되었으며, ELMo표현이 최상의 전체 성능을 제공했다.
- 람다가 클수록(=1) 가중 함수를 단순 평균 함수로 하였으며, 람다가 작을수록(=0.001) layer 가중치를 서로 달라지게 했다.
- 결과적으로, 모든 layer를 사용하는 것이 더 나은 성능을 보였으며, 가중합 시 더 좋은 성능을 나타냈다.
5.2 Where to include ELMo?
- 이 작업에서는 ELMo가 작업 모델에 포함된 위치를 파악한다.
- 본 논문에서 단어 embedding을 biRNN의 최하층에 넣었으며, 일부 task에서는 biRNN의 출력에 ELMo를 포함했다. 이에 따른 결과가 Table 3에 해당된다.
- SQuAD, SNLI는 biRNN 뒤에 Attention layer를 사용했으며, 이 layer에 ELMo를 추가하는 것은 biRNN의 내부 표현을 직접 접근이 가능하게 한 것이다.
- SRL은 task 특성화 문맥 표현이 더 중요하다.
5.3 What information is captured by the biLM's representations?
- 해당 분석에서는 biLM에서 캡처된 다양한 유형의 context 정보 탐색과 2개 고유 평가를 사용한다.
- ELMo를 추가하는 것으로도 단어 벡터만 있을 때보다 성능이 향상된다. biLM의 문맥적 표현은 단어 벡터가 잡아내지 못한 정보를 갖고 있어야 한다. (biLM은 다의어를 구분할 수 있는 정보를 가지고 있어야 함)
- GloVe는 play라는 단어에 고정된 의미를 부여하여 유사한 단어들도 한정적이지만, ELMo의 경우 역할 수행/희곡과 같은 의미의 play를 구분할 수 있다.

Word sense disambiguation
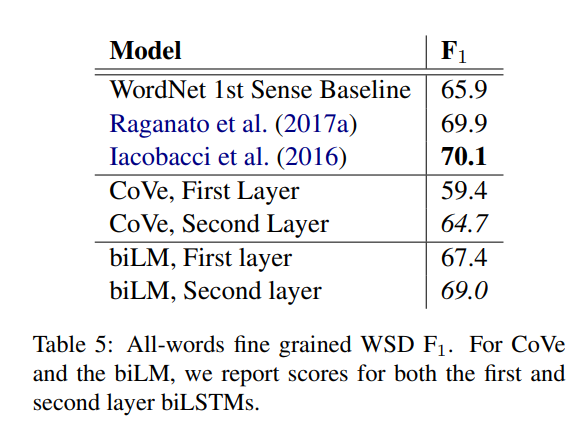
POS tagging

Implicatoins for supervised tasks
- 이러한 앞선 실험들은 biLM에서 모든 layer가 중요한 이유를 알려준다. 즉, 각 layer마다 잡아낼 수 있는 문맥 정보가 다르기 때문이다.
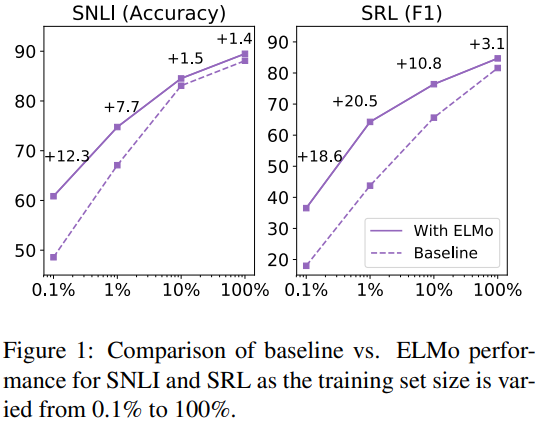
5.4 Sample efficiency
- ELMo를 추가했을 때 학습 속도가 빨라지며(49배가량), 학습 데이터가 적을 때도 효율적으로 학습한다.
5.5 Visualization of learned weights

- 입력 layer에서 coreference, SQuAD에서 1st biLSTM layer를 선호, 출력 layer에서 낮은 layer에 조금 더 중점을 두지만, 상대적으로 균형 있는 모습을 알 수 있다.
6 Conclusion
- biLM을 이용한 높은 성능의 deep context-dependent representation, ELMo를 제안한다. ELMo를 추가한다면 다양한 NLP tasks에서 좋은 성능을 낼 수 있었다.
- 또한, biLM 계층이 문맥 내 단어에 대한 다양한 유형의 구문, 의미 정보를 효율적으로 인코딩하고 모든 계층을 사용하여 전반적인 작업 성능의 향상을 보여준다는 것을 확인했다.
'또치의 AI 공부정리 > NLP 논문 정리' 카테고리의 다른 글
| Attention Is All You Need(Transformer) (0) | 2022.01.18 |
|---|---|
| Neural machine translation by jointly learning to align and translate(Attention) (0) | 2022.01.10 |
| Sequence to Sequence Learningwith Neural Networks(Seq2Seq) (0) | 2021.12.21 |
| Distributed Representations of Sentences and Documents(Doc2Vec) (0) | 2021.12.09 |
| Distributed Representations of Words and Phrasesand their Compositionality (0) | 2021.10.30 |