이번 페이지에서 정리하고자 하는 NLP 논문은 Word2Vec의 발전모델을 구현한 모델을 제안한 논문이다.
혹시 Word2Vec논문을 읽지 않았다면, 이전 링크를 참고해보도록 하자.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111-3119).
Abstract
- 본 논문은 skip-gram model의 확장 모델을 소개한다.
- 저자들은 추가적으로 모델에 적용된 방법을 통해 단어 벡터 quality를 향상하고 훈련 속도 개선을 보여준다.
- 특히, 빈도수 높은 단어의 subsampling을 사용하여 상당한 속도 향상과 regular 한 단어 표현을 더 많이 학습할 수 있다.
- 그리고 계층적 softmax을 간단하게 수정하여 새로운 기법을 소개했는데 그것이 "negative sampling"이다.
- 추가적으로, 단어 표현의 근본적인 제한점은 단어 순서를 고려하지 못함과 동시에 관용구를 표현하지 못함에 있었다.
- 예를 들어, "Canada"와 "Air"의 각각의 의미와 "Air Canada"가 의미하는 것은 다르다. 이러한 관용구를 단어 벡터 표현으로 고려하는 것이 불가능했다.
- 이러한 점을 모티브로 하여 text안에서 관용구를 찾기 위한 simple method를 제한하고, 이를 통해 관용구의 벡터 표현 학습을 가능하게 한다.
1 Introduction
- 이전의 모델에서 Skip-gram 모델이 소개되었다. 이 모델은 대량의 비정형 텍스트로부터 좋은 품질의 단어의 벡터 표현을 생성하는데 효과적이다.
- Skip-gram 모델은 dense matrix 곱을 포함하지 않았으며, 이러한 점이 훈련을 효과적으로 만들었다.
- neural network를 사용하여 단어 표현을 계산하는 것은 매우 흥미로운 일이다. 왜냐하면, 학습된 벡터는 많은 언어적 규범과 패턴을 인코딩하기 때문이다. 그리고 이러한 많은 패턴들은 선형 번역으로써 표현 가능하다.
ex) vec("Madrid") - vec("Spain") + vec("France") =? >>? 의 벡터는 vec("Paris")에 가깝다.
- 이러한 맥락과 함께, 본 논문에서는 Skip-gram 모델을 몇 개의 연장을 제안한다.
1) 빈도수가 높은 단어들에 대해 sub-sampling 하기
2) Skip-gram 모델 훈련을 위해 Noise Contrastive Estimation (NCE)의 간단한 버전을 사용한다. 이는 빈번한 단어들의 빠른 훈련 속도와 더 나은 벡터 표현을 가능하게 한다. 이 방법은 이전에 사용된 계층적 softmax대신 NCE의 변형 버전을 이용하는 것이다.
- 앞서 언급했듯, 개별 단어를 결합하지 못해 관용구를 표현하는데 한계가 존재했다. 그래서, 본 논문에서는 모든 관용구에 대해 벡터 표현(recursive autoencoders와 같은 것)을 사용한다.
- 단어 기반 관용구를 고려하는 모델의 확장을 위해
1) data-driven 접근법을 사용하여 대량의 관용구를 입증한다. 그리고, 훈련 도중 개별 토큰을 관용구를 다룬다.
그리고, 관용구 벡터의 품질을 평가하기 위해, 우리는 단어와 관용구를 포함하는 analogical reasoning task의 테스트 셋을 개발한다.
ex) "Montreal" : "Montreal Canadiens" :: "Toronto" : "Toronto Maple Leafs"
>> vec("Montreal Canadiens") - vec("Montreal") + vec("Toronto") = vec("Toronto Maple Leafs")
2) 간단한 벡터 더하기는 종종 의미 있는 결과를 낸다는 점을 고려한다.
ex) vec("Russia") + vec("river") ~= vec("Volga River")
즉, 언어 이해의 불명확함은 단어 벡터 표현에서 수학적 연산을 사용하여 얻어질 수 있다.
2 The Skip-gram Model
- Skip-gram 모델은 문서나 문장에서 주변 단어를 예측한다.
- 이 모델의 목적 함수는 평균 로그 확률을 최대화한다.


- (1) 공식에서 c는 training context의 size이다. wt는 중심 단어를 의미한다.
- 더 큰 훈련 예시에서 c는 더 커진다. 그리고 훈련 시간의 확대와 함께 높은 정확도를 갖게 한다.
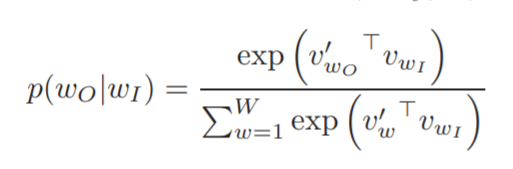
- softmax function을 사용하여 Skip-gram 공식을 정의하면 (2)와 같다.
- vw와 vw'는 각각 w의 input, output vector 표현이다. 그리고 W는 vocabulary에 있는 단어 수이다.
- 이 공식은 실용적이지 못하다. 왜냐하면, (2)를 편미분 시 W에 비례하게 된다. 그리고 이는 10^5~10^7의 크기를 갖기 때문이다.
2.1 Hierarchical Softmax
- neural network에서 확률 분포를 얻기 위한 W output 노드의 계산 대신에, log_2(W)를 사용한다.
- 계층적 softmax는 각 노드를 위해 W단어와 함께 output layer의 binary tree 표현을 사용한다.
이것은 단어에 확률을 배정한 random walk로 정의한다.
- 더 정확하게, 각 단어 w는 나무의 root로부터 적절한 path에 의해 도달할 수 있다. n(w, j)는 루트에서 w까지의 path에서 j번째 node이다. L(w)는 path의 길이이다. (즉, n(w, 1) = 루트에서 w까지의 path에서 1번째 node, n(w, L(w)) = w)
- innder node n에 대해 ch(n)는 n번째 노드의 자식 node를 의미한다.
- [[x]]는 만약 true라면 1 아니라면 -1이 배정된다.

- 윗 식의 의미를 이해하기 위해 괄호( ) 안을 살펴보자.
1) [[ ]]의 좌항은 root에서 w까지의 path 중 j+1번째 노드이다. 우항은 root에서 w까지의 path 중 j번째 노드에 대한 자식 노드를 의미한다. 이 둘이 같으면 1, 다르면 -1이 된다. 이것은 tree의 왼쪽과 오른쪽 경로 설정 파트이다.
2) vn'(w, j)는 이진트리의 inner 노드 n이다.
3) vw_I는 input word vector이다.
>> 즉, input word vector에 대하여, 내부 노드 n개까지 이진트리를 통해 경로가 설정되며 좌/우 경로에 대한 방향성은 1 또는 -1로 설정되는 것이다. 결과적으로 이 값에 대해 sigmoid 확률 값들이 추출되며, 이들을 모두 곱한 것이 (3)의 결과이다.
- logp(wO|wI)의 미분 값은 L(wO)이며, 이 값은 logW보다 더 크지 않은 평균값을 갖는다.
- Skip-gram은 각 단어 w에 대해 vw와 vw'라는 두 개의 표현을 갖는다.
반면 계층적 softmax 공식은 vw라는 하나의 표현과 binary tree의 내부 노드를 위한 vn'을 갖는다.
- binary Huffman tree 사용하면, 빈번한 단어에 대한 짧은 코드와 함께 빠른 훈련이 가능하다.
*Note : Hauffman tree
- 문자열의 빈도수를 트리에 이용해 2진수로 압축하는 알고리즘
예를 들어, [a, b, c, d, e, f]라는 문자열이 있다고 가정하자. 이때, 각 문자에 대한 숫자 빈도수는 [2, 3, 5, 7, 9, 13]이라고 하자.
빈도수를 합해서 상위 노드까지 tree구조를 확장시킬 때, 임의의 두 빈도수 합이 작게 전개되도록 tree 구조를 확장한다.
그럼 최상위 노드의 값은 39가 되고 이를 기준으로 좌측은 1, 우측은 0을 가지에 배열한다. (빈도수를 큰 순서로 나열했다면 좌측에 0, 우측에 1을 지정)
결과적으로, 2라는 빈도를 가진 a의 이진 코드는 1111이 되고, 3은 1110, 5는 110, 7은 1, 9는 0을 갖는다.
그러므로, 만약 새로운 문자열의 배열이 aabcdef 일 때, 1111 1111 1110 110 1010 (19bit)의 이진 코드 값을 갖게 된다.
2.2 Negative Sampling
- 계층적 softmax의 대안으로 Noise Contrastive Estimation (NCE)를 사용하고자 한다.
- NCE는 로지스틱 회귀에 의해 데이터의 노이즈로부터 분별을 가능하게 한다. 즉, 로그 확률의 근사를 최대화한다. 한편, Skip-gram은 quality 있는 벡터 표현 학습에 집중한다.
- 그렇기 때문에, 저자들은 한 층 더 나아가 quality를 유지하면서, NCE를 간단히 하고자 했다. 그래서 새롭게 정의한 것이 Negative Sampling 기법이다.
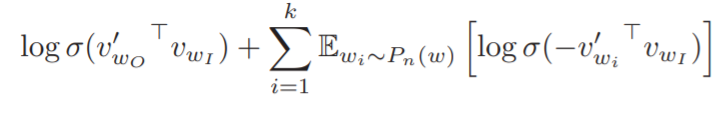
- 기존의 Skip-gram은 중심 단어가 모델에 대입되면, 그에 대한 주변 단어를 출력했다. 하지만, Negative Sampling기법을 함께 사용하면, 중심 단어와 주변 단어일지 혹은 아닐지 모르는 단어를 같이 대입한다. 그리고, 결과로 확률을 출력하게 된다. 이는 두 단어가 실제로 윈도우 크기 내 존재하는 이웃일지 확률 조사를 하는 것이다.
- (4) 식의 의미는 (input/output word 벡터의 확률을 고려하는 항) + (input, i th 단어 벡터의 내적 값에 대한 log-sigmoid; noise분포를 고려하는 항)에 해당한다. 여기서, 두 번째 term은 무작위로 선택된 주변 단어가 아닌 일부 단어들을 가지고 고려한다.
- 두 번째 term의 sigma 범위에서 k는 작은 data를 사용하는 경우 5-20 사이의 값을, 큰 data를 사용하는 경우 2-5의 값을 갖게 된다. Pn(w)는 noise분포를 의미하며, vw_I는 Input 단어 벡터이다.
- 이 부분은 Skip-gram의 logP(wO|wI)를 대체한다. 그러므로, (4)식을 통해 로지스틱 회귀를 사용하여 노이즈 분포 Pn(w)로부터 타깃 단어 wO를 구별해냄이 주목적이 된다.
- NCE는 노이즈 분포의 수학적 확률과 sample이 필요했던 반면, Negative Sampling은 샘플만 필요하다.
> 즉, NCE는 Softmax의 logP를 최대화한다. 하지만 사실 우리의 적용에는 그다지 필요하지 않다.
>> 그렇기 때문에 NEG는 Numerical Probability가 필요하지 않으며, 특정값을 사용할 필요가 없음을 알 수 있다.
; 여기서는 noise분포에 대한 임의의 값을 unigram 분포 (U(w)^3/4)/Z를 사용한다.
2.3 Subsampling of Frequent Words
- 대용량 말뭉치에서 대부분의 빈번한 단어는 수억 번 등장한다. ex) "a", "the" 등
- 사실 이러한 단어들은 정보 가치를 덜 제공한다.
ex) 동시 발생 빈도를 Skip-gram 모델에 benefit을 제공함에 있어, "France"와 "Paris"가 "France"와 "the"보다 더 높은 benefit을 갖게 된다.
- 또한, 수억 개의 몇 샘플로 훈련 후 빈번히 등장하는 단어들의 벡터 표현은 크게(중요하게) 바뀌지 않았다.
- 그래서, 드물게 등장하는 단어와 빈번한 단어들 사이에 불균형을 조정하기 위해 subsampling 기법을 사용한다.

- P(wi)는 training data set에 있는 단어 wi에 대하여 이 확률 값은 무시한다는 의미를 갖는다.
- t는 threshold이며 여기서는 10^(-5)를 사용한다. f(wi)는 단어 wi의 빈도수이다.
- 즉, t보다 빈도수가 더 큰 단어를 sampling 한다는 의미이다. 만약, 빈번하게 등장한(의미가 덜한;a, the와 같은) 단어라면 P(wi)가 큰 값을 갖게 될 것이다. 그리고 그 기준에 따라(높은 확률로) 무시되는 단어가 된다.
- 비록 이 subsampling 공식은 간단히 추론되었지만, 매우 잘 작동함을 확인했다.
- 학습 가속화에 도움이 되며, 정확도 향상에 도움이 되었다.
3 Empirical Results
- 이 섹션에서는 계층적 softmax(HS), Noise Contrastive Estimation(NCE), Negative Sampling, Subsampling을 평가한다.
- task는 "Germany" : "Berlin" :: "France" :? 와 같은 논리적 구조에 대해 vec(x)를 추론하게 한다. > semantic analogies
- 또한, syntatic analogies 작업도 고려했는데 "quick" : "quickly" :: "slow" : "slowly"와 같은 구조를 의미한다.
>> 즉, 벡터 관계에서 가장 가까운 단어 찾기로 이해하자.
- 저자들은 692,000개의 단어를 사용했는데, 5번 이하로 등장한 단어들은 무시한 것이다.

- Table 1은 Negative Sampling이 계층적 softmax보다 더 나은 수행을 보여줌을 확인해준다. 그리고, NCE보다 근소하게 더 나은 수행을 보였다.
- 빈도수 높은 단어에 대한 subsampling의 적용은 훈련 시간을 개선시켰으며, 더 정확도 높은 단어 표현을 가능하게 했다.
4 Learning Phrases
- 관용구에 대한 벡터 표현을 학습하기 위해 저자들은 우선 같은 문맥에서 동시에 등장하고, 다른 문맥에서는 빈번하지 않게 등장하는 단어들을 찾았다.
ex) "New York Times" 그리고 "Toronto Maple Leafs"는 훈련 data에서 유니크한 토큰이 될 수 있다. 하지만, "this is"는 아니다.
- 이러한 방법으로 vocabulary 사이즈를 많이 증가시키지 않으면서, 의미 있는 관용구를 형성할 수 있었다.
- 이론적으로, Skip-gram은 모든 n-grams을 사용하여 훈련할 수 있지만, 메모리 소모가 매우 크다.
- 그래서, 저자들은 간단한 data-driven 접근법을 사용하여 unigram, bigram기반의 관용구를 사용했다.

- 그리고, (6) score를 사용했는데, 매우 빈번하지 않은 단어들로 구성된 너무 많은 구를 방지한다.
그러므로, 이 score를 넘어선 bigram이 관용구로 결정 난다. 여기서 delta는 discounting 계수이다.
- 만약, 2-4 pass를 넘어서면 threshold를 감소시켜 더 긴 관용구를 형성할 수 있도록 했다.
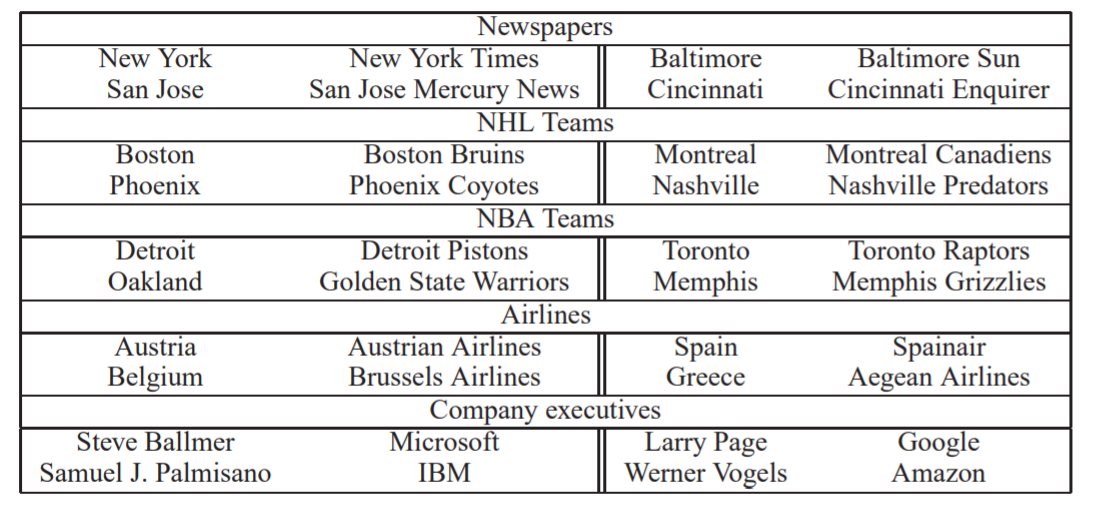
- 그 결과로 얻어진 것이 Table 2이다.
4.1 Phrase Skip-Gram Results
- 우리는 다른 하이퍼 파라미터를 사용하여 Skip-gram 모델을 훈련했다. 이전에는 우리는 300차원과 context size가 5인 모델에서 최상의 결과가 나왔기 때문에 이를 이용하여 Negative Sampling과 계층적 softmax에 적용하여 비교한다.

- 그 결과는 Table 3과 같다.
- Negative Sampling은 k=5보다는 15를 이용할 때 더 나은 결과를 보였다. 놀랍게도, 우리는 계층적 softmax가 subsampling을 하지 않았을 때 매우 낮은 수행을 보임을 알 수 있었다. 즉, 최상의 결과는 빈번한 단어에 대해 down-sampling 하는 것임을 보여준다.
- 즉, subsampling은 빠른 속도와 정확도 개선에 좋은 결과를 보여주었다.
- 관용구의 의미적 task에서 정확도 증가를 위해 우리는 330억 개의 단어 데이터셋을 사용하여 훈련 데이터를 증가시켰다. 그리고 계층적 softmax를 1000차원으로 하여 사용했다. 이를 통해 정확도가 66%에서 72%까지 증가함으로 인해, 큰 데이터 셋이 정확도 향상에 중요함을 확인한다.

- 다양한 모델들을 사용하여 빈번하게 등장하지 않는 관용구의 근접한 이웃에 대한 정보를 탐색한다.
- 결과는 Table 4와 같다. 관용구의 가장 좋은 표현은 계층적 softmax와 subsampling을 함께 사용한 모델이다.
5 Additive Compositionality
- 간단한 벡터 구조를 사용하여 정확한 유추적 의미를 수행하는데 Skip-gram이 좋은 성능을 내도록 한다.
특히, 의미 있는 요소를 결합해 벡터 합으로 표현 가능하다. (Table 5)

- 단어 벡터는 선형 관계에서 입력값과 함께 softmax 비선형성에 대입된다.
- 문장에서 단어 벡터는 주변 단어를 예측하도록 훈련되는데, 벡터는 단어가 나타나는 문맥의 분포를 표현한다.
- 이것은 output layer의 계산된 확률을 로그로 연결하는데, 두 벡터의 sum은 두 문맥 분포의 곱과 연관되어 있다.
- 이 작업은 AND function으로 구현할 수 있다. 이때 높은 확률을 가진 단어들은 높은 확률을 가진 벡터가 되며, 낮은 확률을 가진 단어들은 낮은 확률을 갖는다.
6 Comparison to Published Word Representations
- 이전에 많은 저자들은 단어 표현에 기반한 neural network를 제안했다. 그래서, 이러한 모델들과 함께 비교하고자 한다.
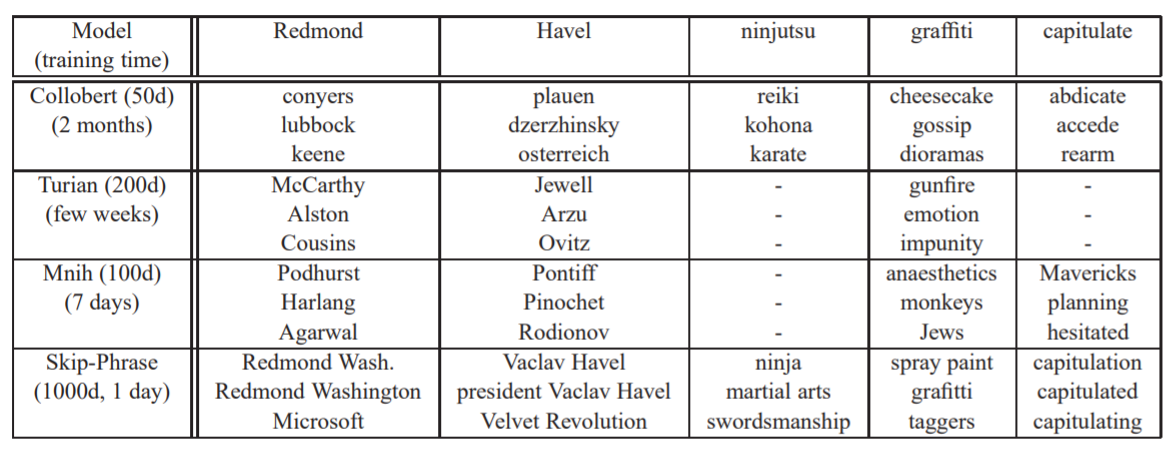
- 학습된 벡터들의 quality의 차이점에 대한 통찰력을 위해, 저자들은 빈번하지 않은 단어들의 근접한 이웃들을 보여줌으로써 비교를 제공한다. (Table 6)
- 이러한 예시는 큰 Skip-gram 모델이 큰 말뭉치를 가지고 훈련한 경우 다른 모델들보다 더 나은 수행을 함을 보여주었다.
- 이 모델은 300억 개의 단어로 훈련되었으며, 일반적인 typical size보다 2-3배 되는 양이다.
- 흥미롭게도, 훈련 셋이 더 커짐에도 불구하고 Skip-gram 모델의 훈련시간은 줄어들었다.
7 Conclusion
- 저자들은 단어 그리고 관용구의 분산 표현을 어떻게 훈련할 수 있는지 보여준다. 그리고, 선형 구조에서 의미 있는 구조를 만들어내기 위한 방법을 증명한다. 이는 Skip-gram 뿐만 아니라, CBOW에서도 사용 가능하다.
- 저자들은 성공적으로 이전에 제안된 모델보다 더 많은 데이터를 이용하여 모델을 훈련에 성공했다. 특히, 단어와 관용구(드물게 등장하는 entities)를 학습하였다. 또한, 빈번한 단어에 대한 subsampling은 더 빠른 학습 속도와 더 나은 정확도를 제공했다. 그리고, Negative sampling 알고리즘은 빈번한 단어들에 대한 정확한 표현을 위한 것으로 제안되었다.
- 물론, Task에 따라 하이퍼 파라미터와 모델을 적절히 선택해야 한다고 서술한다.
특히, 모델 구조 선택, 벡터 사이즈, subsampling 비율, 훈련 window size를 고려해야 할 것이다.
- 결과적으로 흥미로웠던 것은
1) 단어 벡터는 간단히 벡터의 합만으로도 의미 있는 결과를 낼 수 있었다.
2) 관용구의 학습 표현을 위한 접근은 간단한 token들을 통해 이루어졌으며, 관용구가 표현될 수 있었다.
- 이러한 두 가지의 접근법을 통해 계산 복잡성을 최소화하며 text의 긴 조각들을 표현할 수 있었다.
'또치의 AI 공부정리 > NLP 논문 정리' 카테고리의 다른 글
| Attention Is All You Need(Transformer) (0) | 2022.01.18 |
|---|---|
| Neural machine translation by jointly learning to align and translate(Attention) (0) | 2022.01.10 |
| Sequence to Sequence Learningwith Neural Networks(Seq2Seq) (0) | 2021.12.21 |
| Distributed Representations of Sentences and Documents(Doc2Vec) (0) | 2021.12.09 |
| Efficient Estimation of Word Representations in Vector Space(Word2Vec) (0) | 2021.10.28 |