이번 페이지에서 정리하고자 하는 NLP 논문은 Word2Vec이라고 불리는 논문이다.
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
Abstract
- 본 논문의 주목적은 매우 큰 data에서 단어의 연속된 벡터 표현을 계산하기 위해 2개의 모델 구조를 제안함에 있다.
- 성능은 단어 유사도 검증방법과 선행연구에서 수행된 NN 기반 기술의 최고 성능과 비교되었다.
- 특히, 본 논문에서 제안한 모델은 계산 비용을 매우 낮추며 동시에 좋은 성능을 냈다고 정리한다.
- 즉, 16억 개의 단어 데이터 셋으로부터 학습한 word vector들은 높은 성능을 냈다.
1 Introduction
- 선행 연구들을 통해 훈련된 모델이 소량의 데이터로 훈련된 모델보다 더 나은 수행을 보였다.
- 하지만, 간단한 기술에는 몇 가지 제한점이 있다. 예를 들어, 자동화 음성 인식을 위한 관계있는 in-domain data의 양에는 제한이 있었는데, performance에는 오직 수백만 개 정도의 단어만 이용되었다. 기계 번역의 경우 많은 언어를 위한 현존하는 말뭉치도 수십억 개의 단어이거나 적다.
- 즉, 하고자 하는 task에 비해 적은 data를 보유했다.
- 이러한 이유로 basic 기술들의 sacling up 하는 것은 진전 있는 결과를 낼 수 없었고, 그렇기 때문에 우리는 더욱 발전된 기술이 필요했다.
- 이러한 필요성과 함께, 머신러닝 기술의 발전으로 큰 데이터 셋을 훈련할 수 있는 복잡한 모델 설계가 가능해졌다.
- 특히, 단어의 분산 표현을 이용하여 성능을 더 높일 수 있었다.
1.1 Goals of the paper
- 본 논문의 주목적은 앞서 언급하였듯이, 수십억 개 혹은 수백만 개의 거대한 데이터셋으로부터 좋은 품질의 단어 벡터들을 학습해내는 기술들을 소개함에 있다.
- 특히 저자들은, 유사한 단어들이 서로 가까이 있으며, 서로 간 다양한 수준의 유사성을 가지며 품질 측정을 위해 최근 기술들을 사용했다고 서술한다.
- 예를 들어, 형태 변형이 가능한 굴절 언어의 특징을 이용하여, vector 공간에서 유사한 단어를 찾으면, 유사한 끝 형태를 확인 가능하다는 점을 이용한다.
- 다소 놀랍게도, 단어 표현의 유사성은 간단한 구조적 규칙을 넘어섬을 확인한다.
- 그러기 위해, 간단한 대수적 표현법을 이용해서 단어 벡터를 표현하는 방법을 사용했다.
ex) vector("King") - vector("Man") + vector("Woman") = ? ; result = vector("Queen")
- 그러므로, 본 논문에서는 맥락적, 구조적 특징과 함께 test 하고자 한다. 특히, 높은 정확도가 얻어지도록 한다.
- 또한, word vector의 차원과 훈련 데이터양을 기반으로 정확도와 훈련시간을 논의하고자 한다.
1.2 Previous Work
- 선행연구로 제안되었던 Language model은 NNLM(neural network language model)이다. 즉, 단어 벡터들을 훈련할 때 이용 가능하다.
- 이를 확장하여 저자들은 simple model을 사용하여 학습된 단어 벡터들에 초점을 맞추고자 한다.
- 단어 벡터들에 대한 평가는 다른 모델 구조를 사용하여 수행되었으며, 다양한 말뭉치에 의해 훈련되었다.
- 하지만, 훈련에 계산비용이 많이 소모되었다.
2 Model Architectures
- 많은 모델의 다양한 유형들이 단어의 연속적인 표현 평가에 사용되었다. (Latent Semnatic Analysis(LSA)와 Latent Dirichlet Allocation (LDA) 포함)
- 본 논문에서는 NN에 의해 학습된 단어들의 분산 표현에 집중한다. 왜냐하면, LDA의 경우 대용량 데이터 셋에서 계산 비용이 높게 요구되었으며, 단어 사이 선형 규칙성을 유지하기 위한 LSA보다는 더 나은 성능을 갖기 때문이다.
- 특히, 저자들은 모델을 훈련하는데 필요한 파라미터 수를 통해 모델의 계산 복잡도를 정의했다.
- 그리고, 정확도를 최대화하고자 하였으며, 계산 복잡도를 최소화하고자 하였다.
training complexity : O = E x T x Q
(E는 훈련 epoch의 수, T는 훈련 셋의 단어 수, Q는 각 모델에 대해 추가적으로 정의되는 값)
(보통 E는 3~50, T는 최대 10억의 범위 내에서 선택됨)
(모든 모델은 stochastic gradient descent와 backpropagation을 사용하여 훈련됨)
2.1 Feedforward Neural Net Language Model (NNLM)
- input, projection, hidden, ouput layer로 구성
- input layer에서, N개의 이전 단어들은 V의 vocab size에 대해 1-of-V coding(one-hot) 즉, 인코딩 된다. 그리고, projection layer으로 N x D의 차원(P)을 가지고 투영된다. 여기서 N은 보통 10, P는 500~2000차원을 갖는다.
- hidden layer에서는 vocabulary에서 모든 단어들의 확률 분포를 계산하고, 결과를 V차원으로 하는 output layer로 전달한다.
computational complexity per each training example = Q = N x D + N x D X H + H x V
(H는 hidden layer를 의미하며, 보통 500~1000개의 unit을 갖는다)
* Note : 논문외에 추가적으로 참고하면 좋은 내용
- 앞서, projection layer를 이용한다 하였는데, 투사층이라고도 부르는 이 계층은 가중치 행렬과의 연산은 이루어지지만 활성화 함수가 존재하지 않음
- 룩업 테이블(입력값과 가중치 행렬의 곱 결과) 작업을 거치면, 임의의 차원 V를 갖게 된다고 가정하자.
- 이때, 룩업 테이블을 거친 단어 벡터들을 임베딩 벡터라고 한다. 이 임베딩 벡터들은 투사층에서 모두 연결(concatenation)된다.
- 투사층은 활성화 함수를 거치지 않는 선형층인데, 투사층의 결과로 h의 크기를 갖는 hidden layer로 전달되게 된다.
- 저자들은 앞서 언급한, NNLM 모델의 복잡성을 피하기 위해 계층적 softmax를 사용했다.
- 그리고, 정규화되지 않은 모델을 훈련 중에 사용했다. 특히, 이진트리를 사용하여 V를 log_2(V)로 output unit의 수를 줄여주었다.
- 하지만, 대부분의 계산 복잡성은 N x D x H에 의해 발생한다. 그렇기 때문에 저자들이 구성한 모델 구성에서는 hidden layer를 사용하지 않았다. 그래서 softmax 정규화의 효율성에 강하게 의존한다.
2.2 Recurrent Neural Net Language Model (RNNLM)
- NNLM의 특정 제한점을 극복하고자 제안된 language model
- 이론적으로 RNN은 이전 단계의 hidden layer 상태와 현재의 입력과 함께 현재 상태를 결정하게 되며, 이를 통해 단기 기억을 형성한다.
RNN 모델의 training에 따른 complexity = Q = H x H + H x V
- 여기서도, H x V는 계층적 softmax를 이용하여 H x log_2(V)로 output unit 수를 줄여줄 수 있다. 물론, 대부분의 복잡성은 H x H으로부터 온다.
2.3 Parallel Training of Neural Networks (신경망의 병렬 훈련)
- 거대한 데이터 셋을 훈련하기 위해 병렬로 framework를 구성
- 복제된 각 모델은 모든 매개변수를 유지하는 중앙 집중 서버를 통해 병렬로 실행하여 gradient를 업데이트
- 본 논문의 모델은 mini-batch를 사용하며, Adagrad를 사용
3 New Log-linear Models
- 본 논문은 계산 복잡성을 최소화하여 단어의 분산 표현을 학습하는 두 가지 모델 구조를 제안한다.
- 이전 section을 통해 대부분의 계산 복잡성은 non-linear hidden layer 계층에서 발생함을 알 수 있었다.
- 새로운 모델 구조는 두 단계에 걸쳐 학습을 하는데,
첫 번째, 연속된 단어 벡터가 simple model에 의해 학습된다.
두 번째, N-gram NNLM을 그 위에서 학습시킨다.
3.1 Continuous Bag-of-Words Model (CBOW)
- feedforward NNLM과 유사한 모델이지만, non-linear hidden layer 계층을 제거하였으며 projection layer은 모든 단어를 같은 위치에서 투영한다.
- 단어의 순서가 영향을 주지 않기 때문에 bag-of-words(BOW)에 해당한다.
- 4개의 미래 단어(순서상 앞 단어), 4개의 이전 단어(순서상 이전 단어)를 사용하여 로그 선형 분류기를 구축하고 성능을 높인다. 즉, 중심 단어(middle word)를 분류하기 위해 훈련한다.
Training complexity = Q = N x D + D x log_2(V)
- CBOW라고 부르게 되는 이 모델은 문맥(context)의 연속적인 분산 표현을 사용한다.
- 또한, NNLM과 동일하게 모든 단어 위치에 대해 입력/투영 layer 사이의 가중치 행렬을 공유한다.
3.2 Continuous Skip-gram Model
- 이 모델의 경우 현재 단어를 중심으로 같은 문장에 있는 주변 단어들에 대해 classification 한다.
- 즉, 현재 단어를 연속 투영층에 있는 로그 선형 분류기에 대한 입력으로 사용하며, 현재 단어를 기준으로 특정 범위 내 주변 단어를 예측하는 것이다.
- 또한, 거리가 먼 단어는 현재 단어와 덜 연관되어있다고 가정하고 적은 가중치를 부여한다.
Training complexity = Q = C x (D + D x log_2(V))
(C는 단어들의 최대 거리이며, 만약 C = 5로 가정한 경우 각 훈련 단계에서 우리는 1~5 사이의 임의의 랜덤 한 숫자를 선택한다. 즉, window size와 같은 개념이다.)
(R은 중심 단어의 이전과 이후 단어이며, 전/후를 다루기 때문에 Rx2개의 단어 분류가 진행된다.)
(본 논문에서 수행한 실험에서는 C = 10으로 사용했다고 한다.)

4 Results
- 앞서 언급한 대수적 표현 방법에 의해 단어 벡터 표현법을 사용하여 단어 간의 관계를 밝히는 것은 이전의 선행 연구에서도 단어 벡터들의 다른 버전의 성능을 비교하기 위해 사용되었다.
- 저자들은 많은 양의 데이터에 대해 이를 사용하여 고차원 단어 벡터를 훈련하고, 이 결과 벡터를 단어 간의 의미 관계에서 사용 가능하기 때문에 유용하다고 정리한다.
4.1 Task Description
- 의미론적 5개의 타입과 구조적 9개 타입을 포함한 종합적인 테스트 셋을 구성한다.
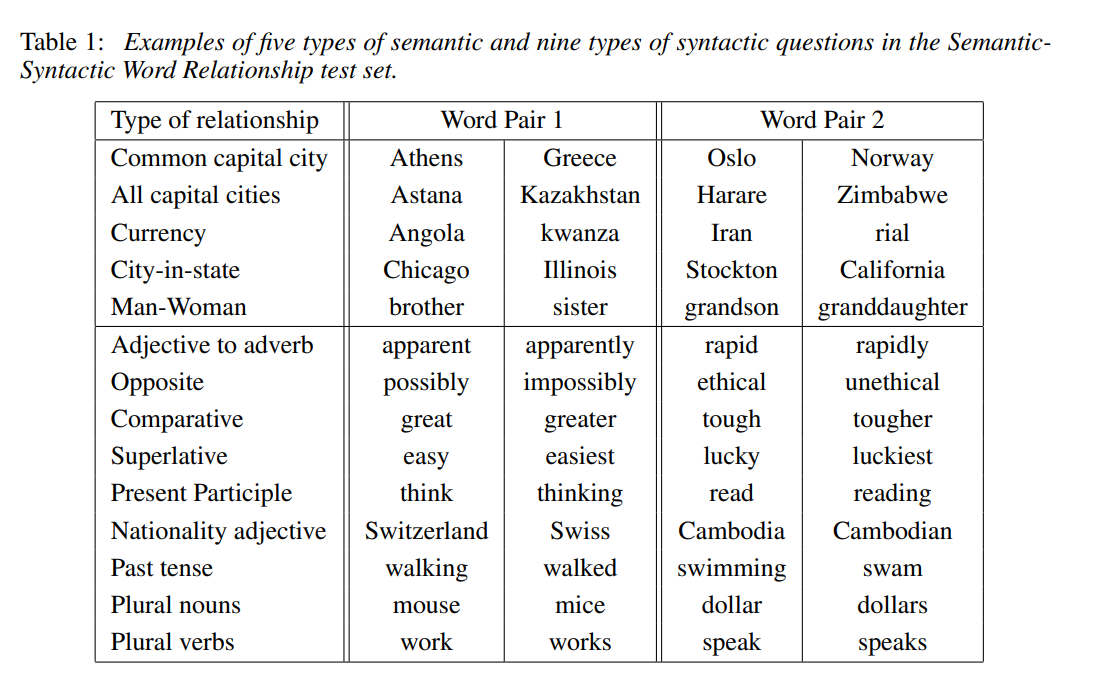
- 각 카테고리 안에 있는 질문들은 두 가지 단계를 통해 만들어진다. 첫 번째, 비슷한 단어 쌍 리스트는 수동으로 만들어진다. 두 번째, 질문의 대형 리스트는 두 단어 쌍의 연결로 구성되었다.
- 또한, 자기 자신과 같은 단어만 정답 처리했으며, 동의어도 mistake 처리했다. 그렇기 때문에 100% 정확도는 초기 설정에 의해 불가능하다.
4.2 Maximization of Accuracy
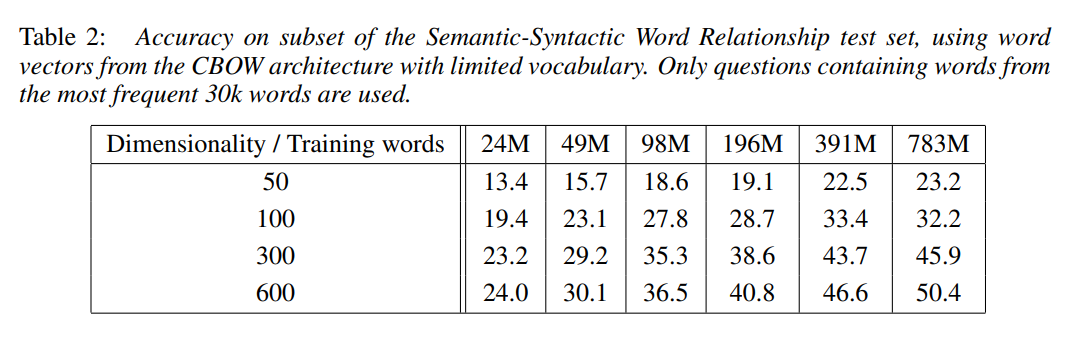
- 단어 벡터들을 훈련하기 위해 구글 뉴스 말뭉치를 이용했다.
- 최대 빈번하게 나온 단어는 백만 개의 vocab size로 제한되었다.
- 저자들은 더 많은 차원 혹은 더 많은 훈련 데이터는 개선을 줄임을 확인했다. 그래서, 벡터 차원과 훈련 데이터의 양을 함께 증가해야만 했다고 한다. 이 부분은 굉장히 당연한 소리로 들릴 수 있다. 그러나, 선행 연구에서 많이 사용된 훈련에는 이러한 조건을 부합하지 않았다고 한다.
- 3개의 훈련 epoch를 사용하며, stochastic gradient descent와 backpropagation을 사용한다.
- 학습률은 0.025에서 시작하여 선형적으로 감소시켰으며 0으로 수렴하도록 한다. (마지막 훈련 시 0에 거의 근접)
4.3 Comparison of Model Architectures
- 같은 훈련 데이터를 통해 훈련하고, 단어 벡터의 차원도 동일하게 하여 다른 모델들과 비교하였다.
- 또한, 단어들 간의 구조적 유사성에 초점을 맞추어 테스트 셋을 이용하였다.
- 훈련 데이터는 LDC 말뭉치를 이용하였다.
- RNN, NNLM 모델 또한 훈련하여 CBOW, Skip-gram과 비교
- CBOW 구조는 NNLM보다 구조적 task에서 더 나은 수행을 보였다.
- Skip-gram 구조는 구조적 task에서 CBOW보다 나쁜 수행을 보였다.(물론 NNLM 보다는 나음) 한편, 의미론적 task에서는 CBOW보다 좋은 수행을 보였다.


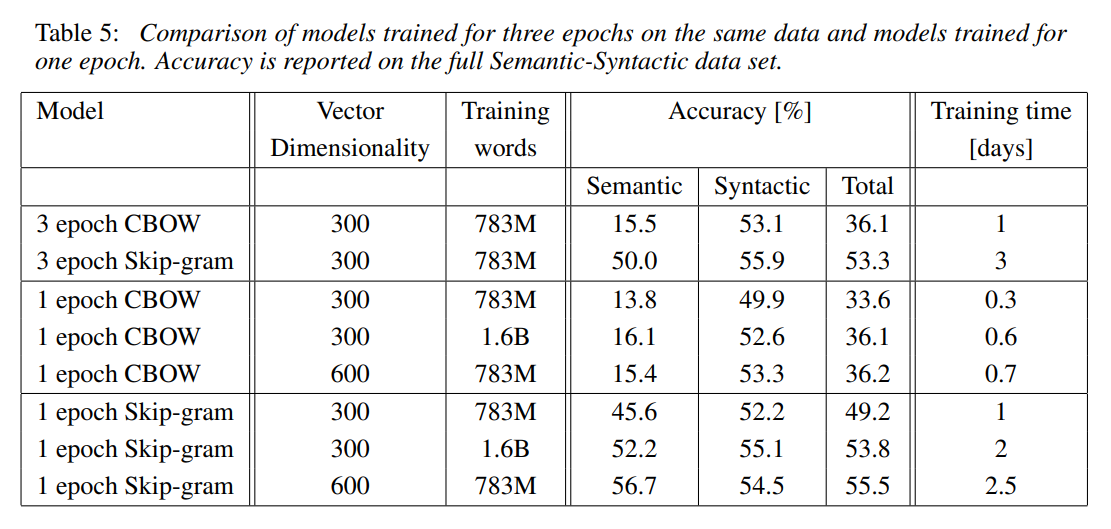
- Table 5에 대해 좀 더 정리하면, epoch가 높을수록 정확도가 좋았다.
- epoch = 1일 때, Skip-gram의 정확도가 높았다.
- 1 epoch CBOW에 대해, training words가 많을수록 정확도가 높았다.
- dimension 차이가 있을 때, dimension이 많을수록 정확도가 높았다.
>> 이 외에도, table을 통해 다양한 조합의 결과를 도출해낼 수 있다.
4.4 Large Scale Parallel Training of Models
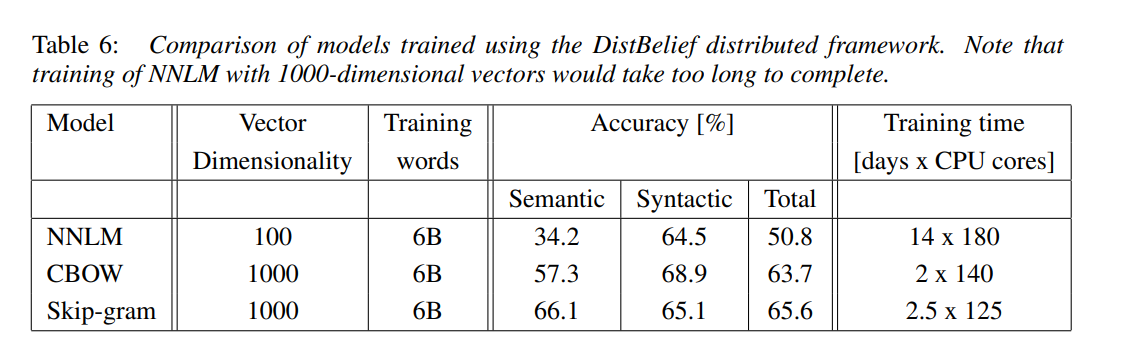
- DistBelief라고 불리는 framework를 통해 다양한 모델을 수행시켰다. (병렬 처리 framework)
- Syntatic 즉, 구조적 task에서 CBOW가 성능이 좋았으며, Semantic 즉, 의미론적 task에서 Skip-gram 성능이 좋았다.
4.5 Microsoft Research Sentence Completion Challenge
- 마이크로소프트 리서치 챌린지는 NLP 기술이나 LM 모델에 대한 task를 소개해왔다.
- 이 task는 1040개의 문장을 보유하고 있으며, 각 문장에서 하나의 단어가 빈칸으로 생략되며 이 부분에 들어갈 가장 적절한 단어를 선택하게 하는 것이 목적이다.
- 저자들은 이를 위해 640차원의 모델을 생성했다. 그리고, 각 문장의 score를 계산했다. 또한, 문장에서 주변 단어를 예측한다. 마지막으로, 문장 score는 각 예측의 sum으로 계산된다.
- 결론적으로, Skip-gram을 단독으로 사용했을 때는 LSA보다도 낮은 성능을 보였지만, RNNLM과 함께 사용 시 가장 높은 정확도를 갖는다.

5 Examples of the Learned Relationships
- 큰 데이터 셋과 큰 차원을 통해 훈련된 단어 벡터는 상당히 더 나은 수행을 보일 것이라 저자들은 예상한다.
- 또한, 정확도를 개선하기 위해서는 단어들 간의 관계를 더욱 제공해야 한다고 제안한다.

6 Conclusion
- 본 논문은 인기 있는 NN(neural network) 모델들과 비교하여 간단한 모델 구조를 사용하여 단어 벡터를 사용했을 때, 성능이 좋았음을 확인했다. 즉, 저자들이 제안한 모델의 우수한 성능을 보여준다.
- 이러한 이유에는 낮은 계산 복잡성을 가질 수 있었기 때문이다. 계산이 간단하기 때문에 대량의 데이터 셋으로부터 높은 차원의 단어 벡터를 매우 정확한 정확도로 계산이 가능했던 것이다.
'또치의 AI 공부정리 > NLP 논문 정리' 카테고리의 다른 글
| Attention Is All You Need(Transformer) (0) | 2022.01.18 |
|---|---|
| Neural machine translation by jointly learning to align and translate(Attention) (0) | 2022.01.10 |
| Sequence to Sequence Learningwith Neural Networks(Seq2Seq) (0) | 2021.12.21 |
| Distributed Representations of Sentences and Documents(Doc2Vec) (0) | 2021.12.09 |
| Distributed Representations of Words and Phrasesand their Compositionality (0) | 2021.10.30 |